




Table of contents
- Advanced Features, Integration, and Real-World Use Cases
- Integration and Compatibility
- Performance and Real-Time Data Analysis
- HarperDB in Real-World Scenarios
- Looking Ahead: The Future of HarperDB
Advanced Features, Integration, and Real-World Use Cases
Introduction
In our initial exploration of HarperDB, we journeyed through its foundational landscape, highlighting the hybrid SQL/NoSQL model and user-friendly data management approach. Building on this, our present discussion ventures into the more intricate workings of HarperDB. We aim to demystify its advanced capabilities, showcase its integration prowess, and illustrate its real-world impact, with a focus on Python-based applications.
Choosing Between HarperDB API and SDK
When interacting with HarperDB, you can either use its RESTful API directly or utilize the HarperDB SDK (like the Python SDK). The choice depends on your project needs, your comfort level with the technologies, and the nature of your tasks. Let's dive into both options with examples to guide you on when to use each.
Using HarperDB RESTful API
When to Use:
Maximum Control: Ideal when you need complete control over the HTTP requests and responses.
No SDK Available: Useful if you're working in an environment or with a language that doesn't have an SDK.
Custom HTTP Handling: Necessary when your application requires specific handling of HTTP connections, like unique timeout settings.
Example: Basic CRUD with RESTful API
Here's how to perform a CRUD operation using Python's requests library:
import requests
url = "http://localhost:9925"
auth = ("your_username", "your_password")
headers = {"Content-Type": "application/json"}
# Inserting a record
data = {
"operation": "insert",
"schema": "your_schema",
"table": "your_table",
"records": [{"name": "John Doe", "age": 30}]
}
response = requests.post(url, json=data, auth=auth, headers=headers)
print("Insert Response:", response.json())
Using HarperDB SDK
When to Use:
Simplicity and Ease of Use: Best for supported languages like Python, offering a more straightforward approach.
Less Boilerplate Code: Ideal if you prefer higher-level abstractions over direct HTTP requests.
Readable Codebase: Suitable when you want to reduce boilerplate code and enhance code readability.
Example: CRUD with HarperDB Python SDK
Performing CRUD operations becomes simpler with the HarperDB Python SDK. Here's how you can do it:
import harperdb
db = harperdb.HarperDB(
url="http://localhost:9925",
username="your_username",
password="your_password"
)
# Inserting a record
schema = "your_schema"
table = "your_table"
record = {"name": "John Doe", "age": 30}
db.insert(schema, table, [record])
Advanced Features and Use Cases of HarperDB
![]()
HarperDB transcends traditional database limits, providing solutions for complex and evolving data needs.
Custom Functions and Complex Data Operations
HarperDB's support for custom stored procedures and advanced query operations empowers users to perform intricate data tasks efficiently.
Custom Stored Procedures
Custom procedures in HarperDB allow for the execution of complex business logic and data manipulation tasks directly within the database. This feature is essential for applications requiring tailor-made data operations without compromising performance.
Advanced Query Capabilities
HarperDB's engine can execute nested queries, joins, and other complex operations. This flexibility is crucial for sophisticated data analysis, enabling users to extract meaningful insights from their data.
Geospatial Data Handling
HarperDB's built-in geospatial capabilities allow for efficient handling of location-based queries, a boon for applications in logistics, urban planning, and location services.
Clustering and Scalability
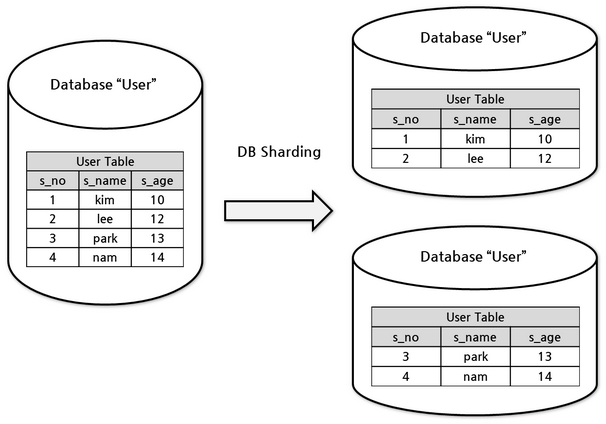
HarperDB's sharding and clustering mechanisms optimize performance and resource utilization, particularly vital in large-scale applications.
Data Sharding
HarperDB's effective sharding distributes data across multiple nodes, enhancing performance and optimizing resource usage.
Cluster Management
HarperDB's cluster management tools offer dynamic scalability and high availability, meeting the high data demands and uptime requirements of large applications.
Integration and Compatibility

HarperDB's integration capabilities ensure seamless operation within diverse tech ecosystems.
Cloud and IoT Integration
HarperDB's adaptability to major cloud platforms and IoT systems stands out, offering robust solutions for cloud-based and IoT applications.
Cloud Services
Seamless integration with AWS, Azure, and GCP makes HarperDB a versatile choice for cloud-based applications, benefiting from cloud scalability and robustness.
IoT Ecosystems
In IoT, HarperDB's efficiency in handling data from numerous sensors and devices, and providing real-time processing, is invaluable.
DevOps and CI/CD Pipelines
HarperDB's smooth integration into CI/CD pipelines supports agile development practices, enabling automated testing, deployment, and database updates.
Performance and Real-Time Data Analysis

HarperDB's standout performance in real-time data scenarios is a key attribute for many modern applications.
Benchmark Analysis
In benchmark tests against other databases, HarperDB consistently shows superior performance in high-concurrency transactions and real-time data processing.
Real-Time Analytics
HarperDB excels in handling streaming data, providing indispensable real-time analytics for industries like finance and social media.
HarperDB in Real-World Scenarios
Exploring HarperDB's application in real-world scenarios reveals its versatility and effectiveness.
Case Studies
HarperDB's application in e-commerce and healthcare demonstrates its ability to handle high transaction volumes and manage sensitive data efficiently.
E-Commerce Platforms
HarperDB manages high transaction volumes and real-time inventory in e-commerce, scaling effectively during peak demand.
Below is an example of a task using API's.
# HarperDB API configuration
url = "http://localhost:<PORT>"
auth = ("your_username", "your_password")
headers = {"Content-Type": "application/json"}
def update_inventory(product_id, quantity):
"""
Updates the inventory for a given product.
"""
data = {
"operation": "update",
"schema": "ecommerce",
"table": "inventory",
"hash_values": [product_id],
"update": {"quantity": quantity}
}
response = requests.post(url, json=data, auth=auth, headers=headers)
return response.json()
Healthcare Data Management
In healthcare, HarperDB's management of patient records and real-time health monitoring data is pivotal, particularly for telemedicine applications.
Below is an example of a task using Python SDK.
import harperdb
# HarperDB configuration
db_url = "https://your-harperdb-instance"
username = "your_username"
password = "your_password"
# Initialize the HarperDB object
db = harperdb.HarperDB(
url=db_url,
username=username,
password=password
)
def update_patient(patient_id, update_data):
"""
Updates an existing patient record.
"""
schema = "healthcare"
table = "patients"
try:
db.update(schema, table, [update_data])
return True
except:
raise Exception(MSG)
def get_patient(patient_id):
"""
Retrieves a patient's record from the database.
"""
schema = "healthcare"
table = "patients"
try:
patient_record = db.sql(f"SELECT * FROM {schema}.{table} WHERE id = {patient_id}")
return True
except:
raise Exception(MSG)
Looking Ahead: The Future of HarperDB
HarperDB is poised not only as a solution for today's data management challenges but is also evolving to meet the demands of future data landscapes.
Upcoming Innovations
Future developments in HarperDB, including the integration of advanced machine learning capabilities and enhanced IoT support, promise to further amplify its robustness and versatility.
Machine Learning Integration
The integration with machine learning frameworks is a significant step forward, poised to bring predictive analytics and data-driven insights directly into HarperDB. This advancement will allow for more sophisticated data analysis and decision-making processes, directly within the database.
Enhanced IoT Support
With a focus on expanding its IoT capabilities, HarperDB is working towards stronger edge computing functionalities and more efficient real-time data processing. This enhancement is crucial for applications where immediate data processing and low-latency responses are critical, such as in smart city infrastructures and industrial IoT scenarios.