

Understanding Errors in Machine Learning

Graduated in 2021. Later worked as an Associate for 6-months in MNC. Later joined the fellowship at BootCamp in backend development. Currently preparing for interviews.
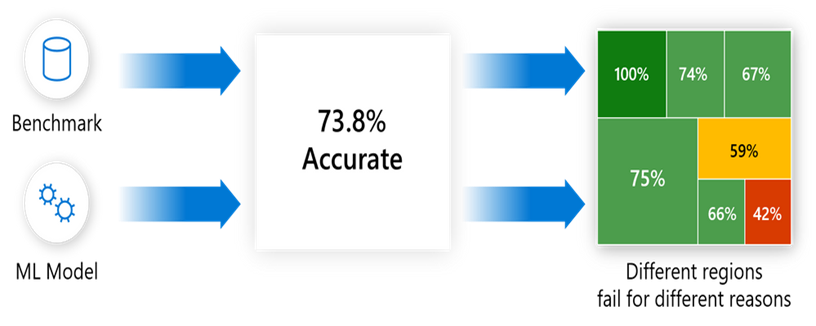
Machine learning is a powerful tool for extracting patterns and insights from data, but it's not without its imperfections. Errors are an inherent part of the machine learning process, and understanding them is crucial for building accurate and reliable models. In this article, we will explore various types of errors in machine learning, including Error, Mean Squared Error (MSE), Residual Error, and others, with real-world examples to illustrate their significance.
Types of Errors in Machine Learning
1. Error
Error, in the context of machine learning, is a measure of how far off a model's predictions are from the true values. It's often expressed as a numerical value that quantifies the discrepancy between the predicted and actual outcomes. The primary goal of any machine learning model is to minimize this error.
Example:
Suppose you are a teacher and you want to predict your students' final exam scores based on the number of hours they spent studying. You collect data from 10 students, recording both the number of hours they studied and their actual exam scores. Here's a simplified dataset:
| Student | Hours Studied | Actual Exam Score |
| 1 | 2 | 60 |
| 2 | 3 | 65 |
| 3 | 4 | 70 |
| 4 | 5 | 75 |
| 5 | 6 | 80 |
| 6 | 7 | 85 |
| 7 | 8 | 90 |
| 8 | 9 | 95 |
| 9 | 10 | 100 |
| 10 | 11 | 105 |
Now, let's say you decide to build a simple linear regression model to predict the exam scores based on the number of hours studied. After training the model, you use it to make predictions for each student. Here's a table that includes the actual exam scores and the model's predictions:
| Student | Hours Studied | Actual Exam Score | Predicted Exam Score (Model) |
| 1 | 2 | 60 | 62 |
| 2 | 3 | 65 | 68 |
| 3 | 4 | 70 | 74 |
| 4 | 5 | 75 | 80 |
| 5 | 6 | 80 | 86 |
| 6 | 7 | 85 | 92 |
| 7 | 8 | 90 | 98 |
| 8 | 9 | 95 | 104 |
| 9 | 10 | 100 | 110 |
| 10 | 11 | 105 | 116 |
Now, let's calculate the error for each prediction:
Error = Actual Exam Score - Predicted Exam Score (Model)
For Student 1: Error = 60 - 62 = -2
For Student 2: Error = 65 - 68 = -3
For Student 3: Error = 70 - 74 = -4
And so on...
These errors represent how much your model's predictions deviate from the actual exam scores. Negative errors indicate underestimation, while positive errors indicate overestimation. The goal of machine learning is to minimize these errors, often using techniques like adjusting model parameters or selecting different algorithms to improve accuracy and make more precise predictions.
2. Mean Squared Error (MSE)
Mean Squared Error (MSE) is one of the most commonly used error metrics in machine learning. It measures the average of the squared errors between predicted and actual values. MSE penalizes larger errors more heavily, making it sensitive to outliers.
The formula for MSE = (1/n) \ Σ(predicted - actual)^2*
Where:
nis the number of data points.predictedis the model's prediction.actualis the true value.
Example:
Suppose you have a regression model to predict the price of a used car based on its age and mileage. You make predictions for 10 cars and calculate the MSE. Here's a simplified example with three cars:
| Car | Actual Price ($) | Predicted Price ($) | Error (Actual - Predicted) |
| A | 10,000 | 9,800 | 200 |
| B | 8,000 | 7,500 | 500 |
| C | 12,000 | 12,200 | -200 |
Now, calculate MSE:
MSE = (1/3) * [(200^2) + (500^2) + (-200^2)] ≈ 116,667
3. Residual Error
Residual error is a specific type of error used in regression analysis. It represents the difference between the observed (actual) value and the predicted value for each data point. Residuals can be positive or negative, indicating overestimation or underestimation, respectively.
Example:
Consider a linear regression model that predicts students' test scores based on the number of hours they studied. After training the model, you use it to make predictions for several students. The residual error for each prediction is the difference between the predicted score and the actual score. Here's a simplified example with three students:
| Student | Hours Studied | Actual Score | Predicted Score | Residual Error |
| 1 | 3 | 75 | 70 | 5 |
| 2 | 5 | 85 | 80 | 5 |
| 3 | 7 | 95 | 100 | -5 |
In this example, Student 1 and Student 2's scores were underpredicted, resulting in positive residual errors, while Student 3's score was overpredicted, resulting in a negative residual error.
4. Absolute Error
Absolute error, also known as mean absolute error (MAE), measures the average absolute difference between predicted and actual values. Unlike MSE, MAE does not square the errors, making it less sensitive to outliers.
The formula for MAE is:
The formula for MAE is:
MAE = (1/n) * Σ|predicted - actual|
Where:
nis the number of data points.predictedis the model's prediction.actualis the true value.
Example:
Continuing with the car price prediction example, calculate MAE for the same three cars:
MAE = (1/3) * [|200| + |500| + |-200|] = (1/3) * (200 + 500 + 200) = 300
5. Mean Absolute Percentage Error (MAPE)
Mean Absolute Percentage Error (MAPE) is a percentage-based error metric that measures the average absolute percentage difference between predicted and actual values. It is commonly used when dealing with forecasts and predictions.
The formula for MAPE is:
MAPE = (1/n) * Σ(|(actual - predicted) / actual|) * 100%
Where:
nis the number of data points.predictedis the model's prediction.actualis the true value.
Example:
Suppose you have a time series forecasting model that predicts monthly sales for a product. After making predictions for 12 months, calculate MAPE using the following data:
| Month | Actual Sales | Predicted Sales |
| Jan | 100 | 110 |
| Feb | 120 | 130 |
| Mar | 90 | 85 |
| Apr | 110 | 105 |
| May | 130 | 125 |
| Jun | 150 | 160 |
| Jul | 140 | 135 |
| Aug | 160 | 150 |
| Sep | 170 | 175 |
| Oct | 180 | 185 |
| Nov | 200 | 195 |
| Dec | 210 | 220 |
Calculate MAPE:
MAPE = (1/12) * Σ(|(actual - predicted) / actual|) * 100%
= (1/12) * [(|10/100| + |10/120| + |5/90| + |5/110| + |5/130| + |10/150| + |5/140| + |10/160| + |5/170| + |5/180| + |5/200| + |10/210|) * 100%]
≈ 7.79%
Conclusion
Errors are an integral part of the machine learning process, and various error metrics help us assess the performance of our models. Whether it's the Mean Squared Error (MSE) emphasizing larger errors, the Mean Absolute Error (MAE) treating all errors equally, or the Mean Absolute Percentage Error (MAPE) for percentage-based assessments, each metric serves a specific purpose in evaluating and fine-tuning machine learning models.
Understanding and appropriately addressing errors is crucial for model improvement and decision-making in real-world applications. By selecting the right error metric and continually refining models to minimize errors, data scientists and machine learning practitioners can build more accurate and reliable systems.




