

Retrieval-Augmented Generation (RAG)
Graduated in 2021. Later worked as an Associate for 6-months in MNC. Later joined the fellowship at BootCamp in backend development. Currently preparing for interviews.
Introduction
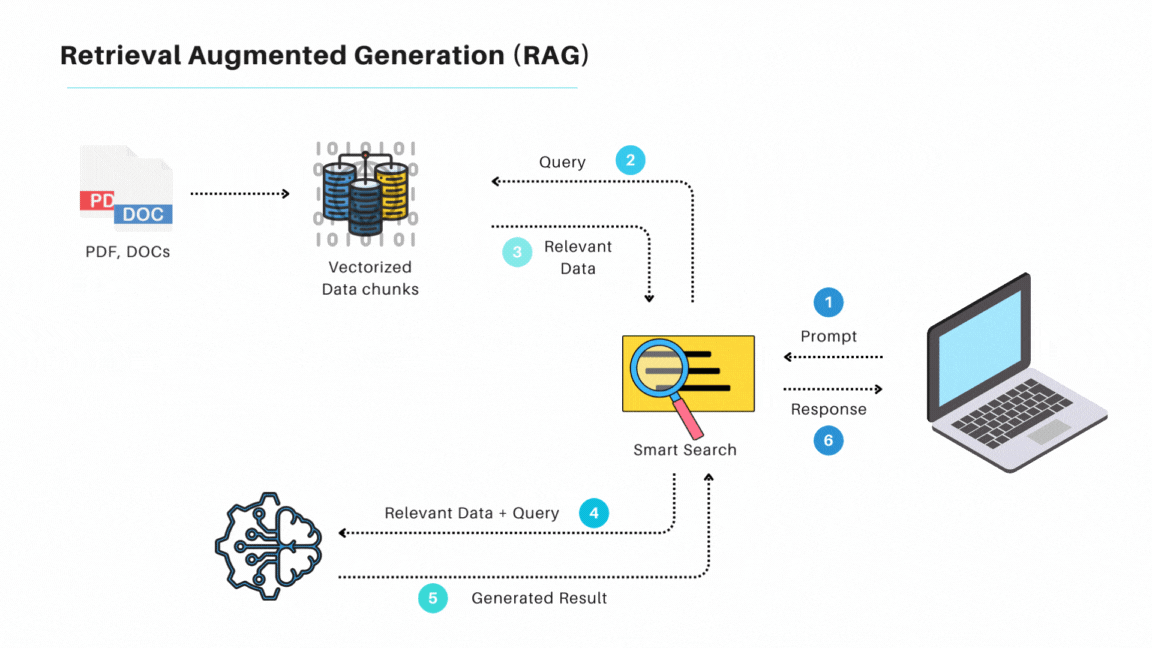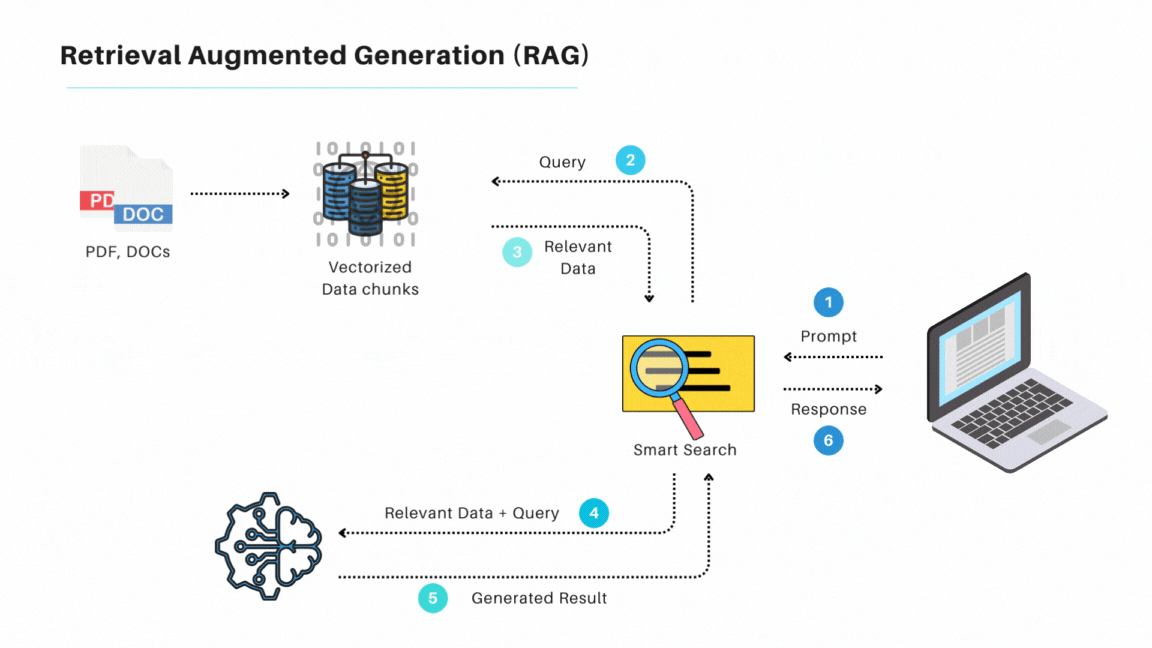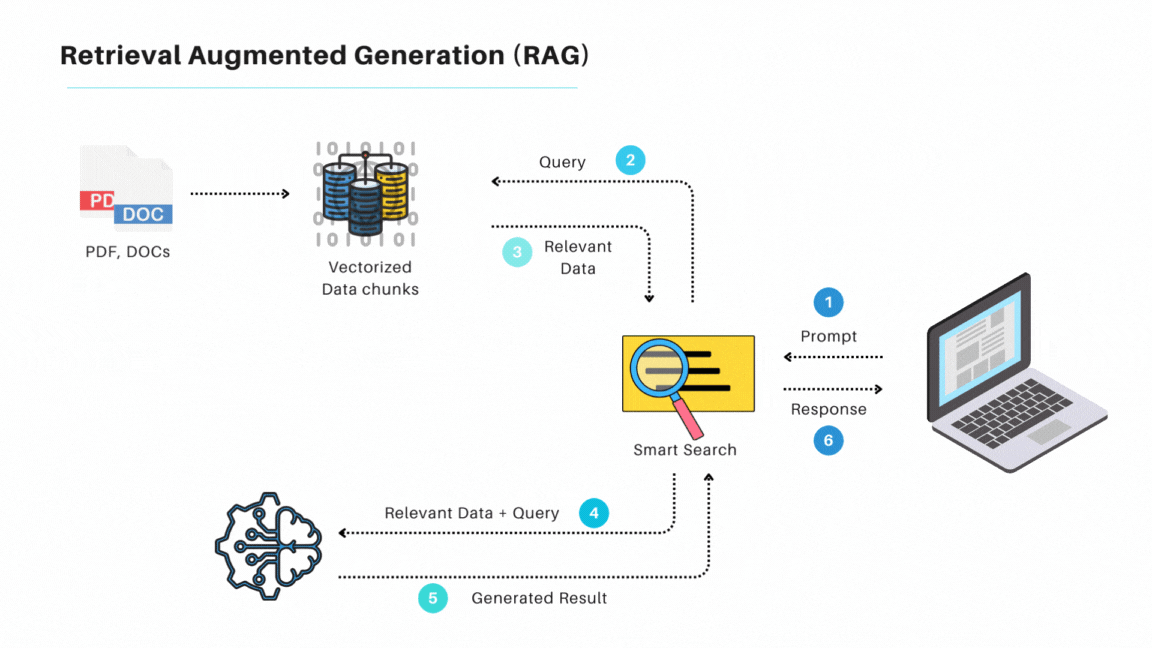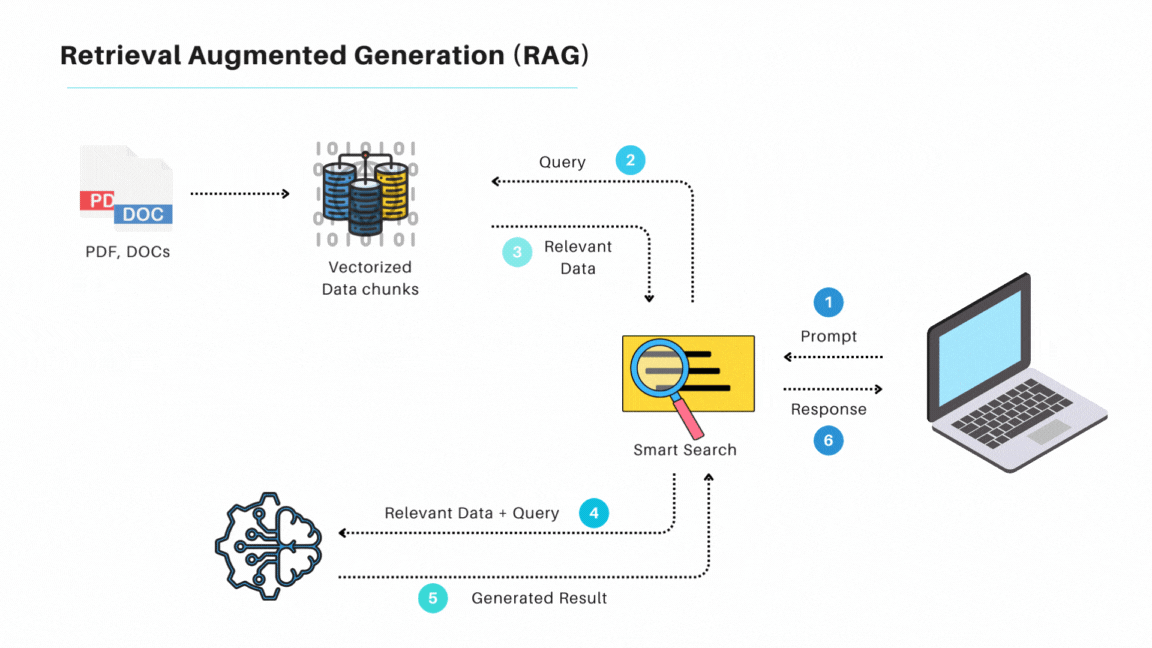
Retrieval-Augmented Generation (RAG) augments a large language model (LLM) with a dedicated retrieval mechanism to ground its responses on external knowledge. This approach improves both the factual correctness and topical coverage of a system’s outputs, compared to relying solely on an LLM’s internal parameters.
Key Concepts
Vector Store: A specialized database (e.g., FAISS, Pinecone) that stores high-dimensional vector embeddings of text.
Embeddings: Numerical representations of text produced by a transformer-based model (e.g., SentenceTransformer).
Chunks: Larger text is divided into manageable segments (for example, 512 tokens each) to enable more efficient and relevant retrieval.
Query: A user prompt or question is also transformed into an embedding, and a similarity search is performed in the vector store to retrieve top-matching chunks.
Augmented Prompt: The retrieved chunks are combined with the user’s query to produce a context-rich prompt for a generative model.
Reference Architecture
A high-level RAG architecture can be outlined as follows:
┌─────────────────────────────────────────────────┐
│ Data Sources │
│ (PDFs, Text Files, Knowledge Bases, etc.) │
└─────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────┐
│ Document Ingestion & Processing │
│ (Extract text, split into chunks) │
└─────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────┐
│ Embedding Generation (Encoder) │
│ (Convert text chunks into vector embeddings) │
└─────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────┐
│ Vector Store (FAISS) │
│ (Store embeddings & metadata for retrieval) │
└─────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────┐
│ Query & Retrieval Steps │
│ (Query → Embedding → Similarity Search) │
└─────────────────────────────────────────────────┘
│
[Retrieved Chunks]
│
▼
┌─────────────────────────────────────────────────┐
│ Generative Model (LLM) │
│ (Combines user query + retrieved chunks) │
│ → Generates final output │
└─────────────────────────────────────────────────┘
Data Ingestion: Raw documents (PDFs, text files, etc.) are processed and split into chunks.
Embedding Generation: Each chunk is converted into a vector embedding.
Vector Storage: Embeddings and associated metadata are stored in a FAISS index (or another vector database).
Query Retrieval: A user query is also embedded; the system retrieves top-matching chunks from the vector store.
Generative Model: The query and retrieved evidence are fed into a language model for the final generated answer.
Implementation
Below is a distilled version of the Python script for a minimal RAG setup. It includes document processing, vector storage with FAISS, and query-based retrieval.
DocumentChunk Data Class
Purpose: Represents a text segment along with relevant metadata (e.g., file name, page number). An embedding attribute can optionally store the vector representation of the text.
import numpy as np
from dataclasses import dataclass
from typing import List, Dict, Any, Optional
@dataclass
class DocumentChunk:
"""
A single segment of text from a document, along with metadata and optional embedding.
"""
text: str
metadata: Dict[str, Any]
embedding: Optional[np.ndarray] = None
VectorStore
import faiss
import pickle
from pathlib import Path
class VectorStore:
"""
Manages storage and retrieval of text embeddings using a FAISS index.
"""
def __init__(self, dimension: int = 384, index_path: str = "vectors"):
self.dimension = dimension
self.index = faiss.IndexFlatL2(dimension)
self.chunks: List[DocumentChunk] = []
self.index_path = Path(index_path)
self.index_path.mkdir(parents=True, exist_ok=True)
def add_chunks(self, chunks: List[DocumentChunk], encoder) -> int:
if not chunks:
return 0
new_embeddings = []
batch_size = 8
# Encode chunks in batches for memory efficiency
for i in range(0, len(chunks), batch_size):
batch = chunks[i : i + batch_size]
texts = [chunk.text for chunk in batch]
embeddings = encoder.encode(texts, convert_to_numpy=True)
new_embeddings.extend(embeddings)
self.chunks.extend(batch)
# Add embeddings to the FAISS index
embeddings_array = np.array(new_embeddings, dtype="float32")
self.index.add(embeddings_array)
self._save_vectors()
return len(new_embeddings)
def search(self, query_embedding: np.ndarray, top_k: int = 3) -> List[DocumentChunk]:
if not self.chunks:
return []
query_embedding = query_embedding.astype("float32")
distances, indices = self.index.search(query_embedding.reshape(1, -1), min(top_k, len(self.chunks)))
return [self.chunks[i] for i in indices[0] if i != -1]
def _save_vectors(self) -> None:
# Save index and chunks
index_file = self.index_path / "faiss.index"
chunks_file = self.index_path / "chunks.pkl"
faiss.write_index(self.index, str(index_file))
with open(chunks_file, "wb") as f:
pickle.dump(self.chunks, f)
def load_vectors(self) -> None:
# Load index and chunks if they exist
index_file = self.index_path / "faiss.index"
chunks_file = self.index_path / "chunks.pkl"
if index_file.exists() and chunks_file.exists():
self.index = faiss.read_index(str(index_file))
with open(chunks_file, "rb") as f:
self.chunks = pickle.load(f)
Key Operations:
add_chunks: Encodes text chunks into embeddings, adds them to FAISS, and saves the index.
search: Retrieves the most similar chunks for a given query embedding.
save vectors / load_vectors: Persists and restores the index and associated chunks from disk.
DocumentProcessor
import tiktoken
from PyPDF2 import PdfReader
class DocumentProcessor:
"""
Processes PDF documents by extracting text and splitting it into tokens.
"""
def __init__(self, chunk_size: int = 512):
self.chunk_size = chunk_size
self.tokenizer = tiktoken.get_encoding("cl100k_base")
def process_file(self, file_path: str) -> List[DocumentChunk]:
text = self._extract_text(file_path)
if not text.strip():
return []
return self._create_chunks(text, {"source": file_path})
def _extract_text(self, file_path: str) -> str:
text_chunks = []
with open(file_path, "rb") as file:
pdf = PdfReader(file)
for page in pdf.pages:
page_text = page.extract_text() or ""
text_chunks.append(page_text)
return "\n".join(text_chunks)
def _create_chunks(self, text: str, metadata: Dict[str, Any]) -> List[DocumentChunk]:
tokens = self.tokenizer.encode(text)
chunks = []
for i in range(0, len(tokens), self.chunk_size):
slice_tokens = tokens[i : i + self.chunk_size]
slice_text = self.tokenizer.decode(slice_tokens)
if slice_text.strip():
chunks.append(
DocumentChunk(
text=slice_text,
metadata=metadata.copy()
)
)
return chunks
Process:
Extract Text: Reads a PDF with
PyPDF2, concatenating the text from each page.Tokenize and Split: Converts the text into tokens and slices them into subgroups of
chunk_size(512 tokens). Each chunk is stored as aDocumentChunk.
RAGSystem
from sentence_transformers import SentenceTransformer
class RAGSystem:
"""
Integrates document processing, vector storage, and retrieval-based querying.
"""
def __init__(self, model_name: str = "all-MiniLM-L6-v2", vector_dir: str = "vectors"):
self.document_processor = DocumentProcessor()
self.encoder = SentenceTransformer(model_name)
dimension = self.encoder.get_sentence_embedding_dimension()
self.vector_store = VectorStore(dimension, vector_dir)
self.vector_store.load_vectors()
def add_document(self, file_path: str) -> int:
"""
Extracts chunks from the PDF, encodes, and adds them to the vector store.
"""
chunks = self.document_processor.process_file(file_path)
return self.vector_store.add_chunks(chunks, self.encoder)
def query(self, query: str, top_k: int = 3) -> List[Dict[str, Any]]:
"""
Retrieves top_k chunks relevant to the query and returns their text/metadata.
"""
query_emb = self.encoder.encode(query, convert_to_numpy=True)
results = self.vector_store.search(query_emb, top_k)
output = []
for chunk in results:
output.append({
"text": chunk.text,
"metadata": chunk.metadata
})
return output
Capabilities:
add_document: Processes and stores a new PDF file.
query: Accepts a user query, embeds it, searches for relevant chunks, and returns them.
Data Privacy Considerations

To maintain data privacy:
Local Storage: All indexing and storage in this example are kept on a local disk, avoiding transfer to third-party services.
Encryption: Optionally encrypt the FAISS index and stored chunks at rest, using tools like PyCryptodome or operating-system-level encryption (e.g., LUKS, BitLocker).
Access Controls: Restrict user permissions to read or update the index.
Private Models: For maximum privacy, use a self-hosted language model (e.g., GPT-NeoX, LLaMA) rather than a remote API.
Example Usage
Below is an example of how you might interact with the RAGSystem from a separate script or within a main function:
def main():
rag = RAGSystem(model_name="all-MiniLM-L6-v2", vector_dir="vectors")
pdf_path = "/path/to/document.pdf"
num_chunks_added = rag.add_document(pdf_path)
print(f"Added {num_chunks_added} chunks from {pdf_path}.")
user_query = "What topics does the introduction cover?"
results = rag.query(user_query, top_k=3)
for i, result in enumerate(results, 1):
print(f"\n--- Top Result {i} ---")
print(f"Text: {result['text']}")
print(f"Metadata: {result['metadata']}")
if __name__ == "__main__":
main()
Github Link: https://github.com/harsha-mangena/LLMS/blob/main/Basic%20Rag/basic-rag.py
Conclusion
The outlined RAG system demonstrates how to integrate:
Document Processing (PDF ingestion, text extraction, chunking)
Vector Storage (FAISS-based search)
Embedding Generation (SentenceTransformer)
Retrieval and Augmentation (Queries that pull relevant text chunks from the vector store)




