




Table of contents
Python, known for its simplicity and readability, is a go-to language for many developers. However, when it comes to concepts like multi-threading and parallel computing, things can get a bit complex. In this article, we'll unravel these concepts, provide examples, and guide you on when to use each. And yes, we'll sprinkle in some humor because who said technical topics have to be dry?
Multi-Threading: The Agile Juggler
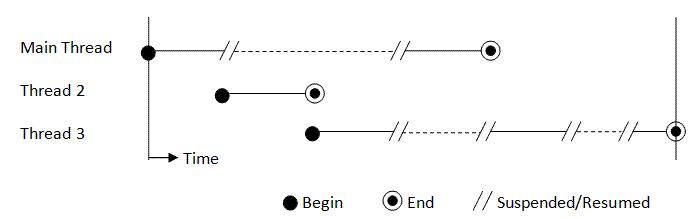
Multi-threading in Python is ideal for tasks that are I/O-bound. It's like a juggler swiftly tossing balls (tasks) in the air, catching and throwing them again without a break. This approach is excellent for when the bottleneck isn't the CPU but waiting for external resources.
When to Use:
I/O-Bound Tasks: Like handling web requests or reading and writing files.
Maintaining Application Responsiveness: Particularly in GUI applications where you don't want the UI to freeze.
Example: Asynchronous Web Requests
Let's say you need to make multiple web API requests. Using multi-threading, you can send requests simultaneously without waiting for each to complete before starting the next one.
import threading
import requests
def fetch_data(api_url):
response = requests.get(api_url)
print(f"Data from {api_url}: {response.text[:100]}...")
api_endpoints = ["https://api.example.com/data1", "https://api.example.com/data2"]
threads = []
for api in api_endpoints:
thread = threading.Thread(target=fetch_data, args=(api,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
print("All API requests completed.")
Comparison with Parallel Computing:
Multi-threading is less about speeding up calculations and more about efficiency in handling tasks that involve waiting.
It doesn't boost performance for CPU-bound tasks due to the Global Interpreter Lock (GIL) in Python.
Parallel Computing: The Power Lifter

Parallel computing in Python, achieved through multiprocessing, is your go-to for CPU-bound tasks. It's akin to a team of powerlifters, each lifting a weight simultaneously. This method truly shines when the task at hand is computation-heavy.
When to Use:
CPU-Bound Tasks: Like heavy calculations, data processing, or complex algorithms.
Handling Large Data Sets: Where computations can be distributed across multiple processors.
Example: Parallel Data Processing
Consider a scenario where you need to process a large dataset, performing a CPU-intensive operation on each element.
from multiprocessing import Pool
def process_data(data):
# Simulate a CPU-intensive task
return sum([i * i for i in range(1, 10000)])
data_set = [item for item in range(100)]
with Pool(4) as p:
results = p.map(process_data, data_set)
print("Data processing complete.")
Comparison with Multi-Threading:
Parallel computing does not suffer from the limitations of the GIL, allowing for true parallelism in CPU-bound tasks.
It's generally not suited for I/O-bound tasks where the main challenge is waiting for external operations.
Making the Choice: Juggling or Lifting?
To decide between multi-threading and parallel computing, assess the nature of the bottleneck in your task.
If your application spends a lot of time waiting for files to be read or written, or for network responses, multi-threading is your ally. It's like having an efficient office worker who can handle multiple phone calls and emails simultaneously.
If your application's primary job is to crunch numbers or process large amounts of data, parallel computing is your champion. It's like a factory with multiple machines working at the same time, each on a different part of the product.
Understanding the E-commerce Backend Landscape
An e-commerce backend system typically handles a plethora of tasks, including:
User Request Handling: Managing user interactions, such as browsing products, adding items to the cart, and checking out.
Payment Processing: Executing and validating payment transactions.
Inventory Management: Updating stock levels based on orders and returns.
Recommendation Engine: Generating personalized product suggestions.
Employing Multi-Threading
User Request Handling
User requests are typically I/O-bound. They involve waiting for client inputs, database queries, and sending responses back to the client. Here, multi-threading can be a game-changer.
Scenario:
Users browsing the website are making multiple requests to view different products.
Each request involves fetching product details from a database.
Implementation:
Using multi-threading, the system can handle multiple such requests simultaneously. This ensures that the website remains responsive, even under high traffic.
import threading
import database_module
def handle_request(user_id, product_id):
product_details = database_module.fetch_product_details(product_id)
# Further processing and sending response back to user
# Thread creation for each user request
threads = [threading.Thread(target=handle_request, args=(user.id, prod.id)) for user, prod in user_requests]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
Leveraging Parallel Computing
Inventory Management and Recommendation Engine
These tasks are CPU-bound, involving complex computations and data processing.
Scenario:
After each purchase, the inventory levels need to be updated across various warehouses.
The recommendation engine processes user data to update personalized suggestions.
Implementation:
Parallel computing allows these tasks to be distributed across multiple CPU cores, speeding up the computations.
from multiprocessing import Pool
def update_inventory(order_details):
# Heavy computational task to update inventory
return result
def update_recommendations(user_id):
# Data processing to generate recommendations
# Parallel processing
with Pool(processes=4) as pool:
# Inventory updates
pool.map(update_inventory, all_order_details)
# Recommendation updates
pool.map(update_recommendations, all_user_ids)
A Hybrid Approach for Optimal Performance
In reality, a hybrid approach that utilizes both multi-threading and parallel computing can often yield the best results.
Multi-threading is used for handling a large number of user requests and payment processing. This ensures the system is responsive and can efficiently handle I/O operations.
Parallel Computing is employed for batch processing tasks like inventory updates and running the recommendation engine algorithms. This is particularly effective for tasks that are not time-sensitive but are computation-intensive.